Understanding metadata
What it looks like, where it lives, and why retrieval depends on it

The article assumes that readers are working with real organizational documents and want to use AI to make those documents more usable. Before any of that becomes possible, there is preliminary work to do, and most of it concerns metadata. This article lays out the conceptual foundation and shows what metadata actually looks like in practice. A separate article post will cover how to generate metadata from existing documents.
The motivation is simple. Almost every AI application built on top of an organization’s existing materials, whether a retrieval-augmented chatbot, a search interface, a classification pipeline, or an analytic dashboard, depends on a layer of structured information that sits between the raw documents and the model. That layer is metadata. If the metadata is thin, inconsistent, or absent, the downstream system will struggle no matter how capable the underlying model is. If the metadata is thoughtful and well-structured, even modest models can do useful work.
What metadata is in this context
Metadata is data about data. The textbook definition is correct but unhelpful for a practitioner. In the context of AI applications built on document collections, metadata is the structured set of fields you attach to each document so that the document can be located, filtered, grouped, summarized, and reasoned about without having to read the document in full each time.
A legal brief has a caption, a court, a docket number, a filing date, a party list, a procedural posture, and a set of issues. A scientific article has authors, an affiliation list, a publication year, a journal, a DOI, a methodological orientation, a population studied, and an outcome focus. A policy document has an issuing body, an effective date, a jurisdiction, a topic area, and a relationship to prior policy. A set of meeting minutes has a date, a body, attendees, agenda items, decisions made, and action items assigned. Each of these is metadata. None of it is the document itself. All of it is what makes a collection of documents searchable as a corpus rather than as a pile.
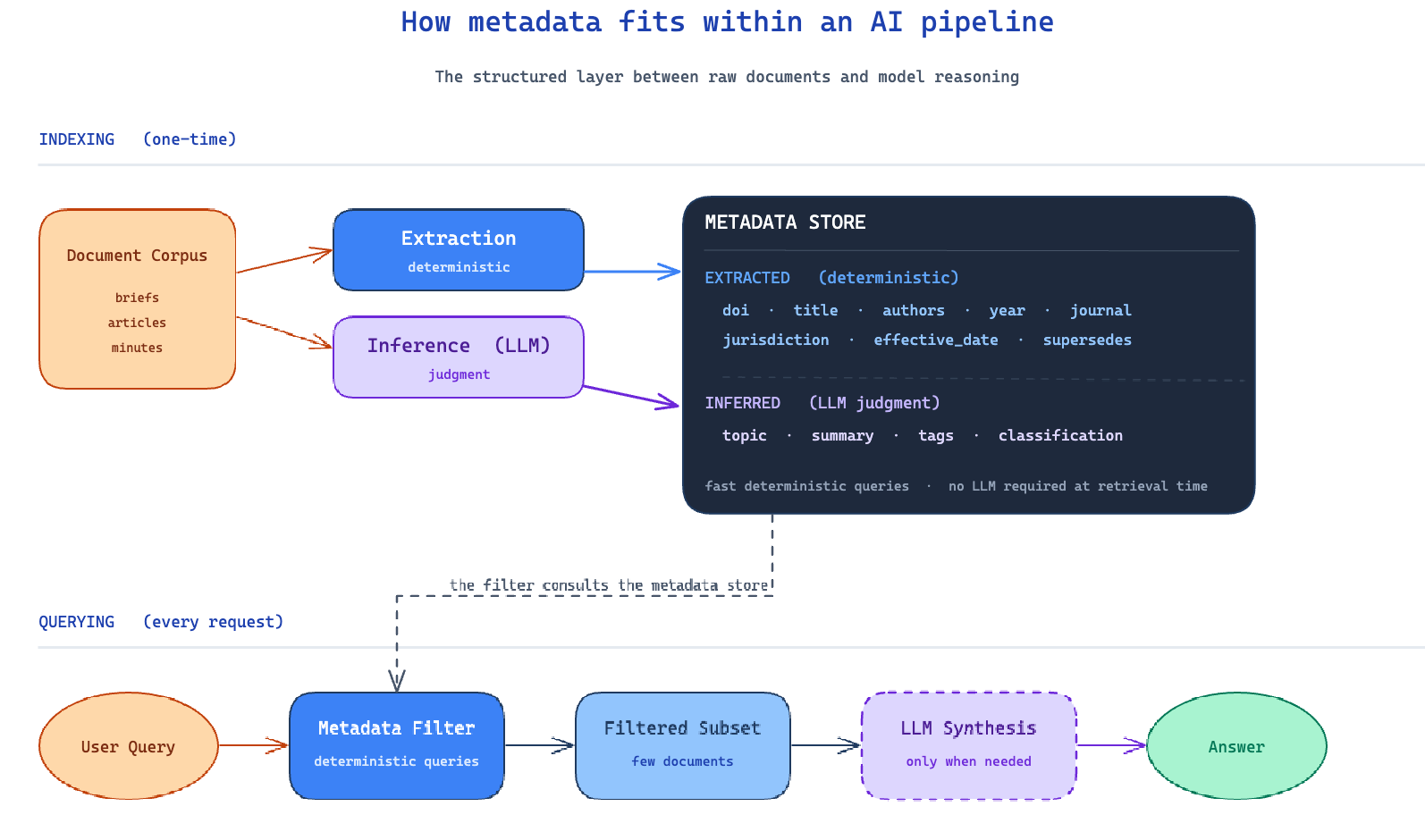
The point of generating metadata is to take an unstructured or semi-structured collection and produce a structured representation that can sit in a database or a flat file and answer questions deterministically. How many briefs were filed in the Eastern District in 2023. Which articles in the corpus involve administrative data. Which faculty meetings discussed the new evaluation policy. None of these questions should require an LLM to answer. They should be answered by querying a well-built metadata table.
What metadata actually looks like
The abstraction becomes much easier to grasp once you see the structure. A metadata record is, at its core, a list of named fields with values. Below are realistic examples for four common document types. The exact fields depend on what you intend to do with the corpus, and a real project would refine these substantially. The point here is to show the form.
A scientific article record might look like this:
{
"doi": "10.1080/02615479.2023.2189456",
"title": "Predictors of foster care reentry among adolescents",
"authors": ["Smith, J.", "Lee, K.", "Anderson, R."],
"journal": "Children and Youth Services Review",
"year": 2023,
"volume": 145,
"pages": "106789",
"study_design": "secondary_analysis",
"data_source": "state_administrative",
"population": "adolescents_in_foster_care",
"open_access": true
}A state policy document record might look like this:
{
"document_id": "FFPSA-MI-2022-001",
"issuing_body": "Michigan Department of Health and Human Services",
"jurisdiction": "Michigan",
"title": "Family First Prevention Services Act State Plan",
"effective_date": "2022-10-01",
"supersedes": "FFPSA-MI-2021-003",
"topic_area": "child_welfare_prevention",
"page_count": 87,
"summary": "State plan describing evidence-based prevention services for candidates for foster care, including service array, evaluation strategy, and workforce supports."
}A faculty meeting minutes record might look like this:
{
"meeting_id": "FAC-2024-09-14",
"body": "School of Social Work Faculty Meeting",
"date": "2024-09-14",
"attendees_count": 32,
"agenda_items": ["budget update", "curriculum review", "promotion guidelines"],
"decisions": ["approved revised PhD comprehensive exam policy"],
"action_items": ["curriculum committee to circulate draft by 10/15"],
"summary": "Discussion centered on revised promotion guidelines and the proposed comprehensive exam policy, which was approved with minor amendments."
}A legal brief record might look like this:
{
"case_caption": "People v. Johnson",
"court": "Michigan Court of Appeals",
"docket_number": "365432",
"filing_date": "2024-03-15",
"filing_party": "appellant",
"procedural_posture": "appeal from summary disposition",
"issues": ["due process", "evidentiary ruling", "ineffective assistance"],
"page_count": 42,
"summary": "Appellant challenges the trial court's grant of summary disposition, arguing improper exclusion of expert testimony and ineffective assistance of trial counsel."
}Several things are worth noticing about these examples.
First, every record uses the same structure within its corpus. Every scientific article record has the same fields. Every policy document record has the same fields. The structure is what makes the collection queryable. A field that exists for some documents and not others is either a sign that the corpus is mixed or a sign that a missing value should be recorded explicitly rather than left out.
Second, the fields are short and discrete. Authors are a list of names. The year is a four-digit integer. The jurisdiction is a single value drawn from a controlled list. Issues are a list of short tags. The summary is a single paragraph. Nothing in the metadata is the document itself. The metadata is meant to be small and fast to query.
Third, the fields differ by document type because the questions you would ask differ by document type. You ask about journals, populations, and study designs in a scientific corpus. You ask about jurisdictions, effective dates, and superseding relationships in a policy corpus. You ask about courts, dockets, and procedural posture in a legal corpus. Designing the metadata schema is partly an exercise in anticipating the questions the corpus will need to answer.
Where metadata lives
Metadata can be stored in several formats. The format you choose depends on how you plan to use it, but the underlying content, the field-value pairs, is the same across formats.
JSON is the dominant format for AI applications and for any workflow that involves nested fields, lists, or programmatic access. The records above are written in JSON. Every record is an object containing fields and values, and a corpus is typically stored as a list of such objects or as one JSON file per document. JSON handles lists (multiple authors, multiple agenda items) and nested structures (parties with sub-fields) naturally, which is why it has become the default for AI pipelines. A subsequent post will cover JSON in more depth.
CSV is appropriate when every field is simple and the metadata is genuinely tabular. A corpus of scientific articles where every record has a title, year, journal, and DOI fits cleanly into a CSV. The moment you need lists, nested objects, or variable-length fields, CSV starts to strain. Workarounds, such as comma-separated values inside a single cell or multiple rows per document, undermine the very querying benefits the format is supposed to provide.
Database tables are the right home for metadata that will be queried frequently or by multiple applications. A relational database, including lightweight options like SQLite, gives you indexing, fast filters, and the ability to join metadata with other tables. Most production systems that begin with JSON or CSV metadata eventually migrate to a database when query load grows.
YAML appears occasionally, usually for metadata that is hand-edited or read by humans alongside machines. It is more forgiving to write than JSON but is rarely the right choice for large generated corpora.
Document-embedded metadata also exists, in the form of PDF document properties, Word file metadata, EXIF tags on images, and so on. This is real metadata, but it is generally a starting point rather than a destination. For AI applications, you will almost always extract embedded metadata into one of the structured formats above so that it can sit alongside the metadata you generate yourself.
The format is a logistical choice. The fields, their definitions, and the consistency of their application across the corpus are the substantive choices. A well-designed metadata schema can be ported between formats with minimal loss. A poorly designed one will be useless in any format.
Extraction versus inference
The conceptual move that matters most is the distinction between metadata that can be extracted directly from a document and metadata that requires inference.
Extraction is straightforward. The author names are on the first page. The filing date is in the caption. The journal title is in the citation. The agenda is at the top of the minutes. When a model is asked to extract this kind of metadata, the task is to locate and copy text that already exists in the source. Reliability is high. Validity is largely a matter of whether the model has correctly identified the boundaries of the field. Errors tend to be specific and detectable, and they can usually be corrected with better prompting, better preprocessing, or fallback rules.
Inference is a different kind of task. If the metadata field is something like “primary methodological approach” or “policy domain affected” or “tone of the deliberation,” the model is no longer copying text. It is reading the document and producing a judgment that may or may not appear anywhere in the source verbatim. This work can still be useful, but it is a categorically different task with categorically different evaluation requirements. Inferred fields need reliability and validity analyses appropriate to classification or labeling work. They need ground-truth comparisons, inter-coder agreement checks, and explicit decision rules. They cannot be treated as if they were extractions even when they end up in the same JSON object.
The trouble starts when these two kinds of work are blurred. A pipeline that mixes extraction fields and inference fields without acknowledging the distinction will produce a metadata table that looks uniform but is not. Some of the fields will be near-deterministic and some will be classification outputs with unmeasured error rates. Downstream queries against that table will return results that appear authoritative but are partly the product of unvalidated inference. The fix is not to avoid inference. The fix is to label the two kinds of fields differently, evaluate them differently, and document their different epistemic statuses.
There is a gray area, and it is worth naming. Some fields look like extractions but require a small amount of normalization or interpretation. A jurisdiction field might be extracted from the caption but standardized against a controlled list. A publication year might be extracted but reconciled across the print and online versions. The summary fields shown in the examples above are inferred, not extracted, even though they may appear to live comfortably alongside the extracted fields. These cases sit at varying distances from pure extraction, and each introduces decisions that should be documented and tested. Treating them carelessly is how downstream errors compound.
The principle of a single table
Metadata generation only works when the collection is coherent. The simplest way to think about this is to imagine that the output will populate a single table in a database. Every row is a document. Every column is a field. Every document in the collection has the same fields, defined the same way, generated by the same process.
This means that a metadata workflow should not mix fundamentally different kinds of documents. A collection of state policy documents can be processed together. A collection of case notes can be processed together. A collection of conference abstracts can be processed together. The fields appropriate for each will overlap in places and diverge in others, but each is a coherent corpus on its own terms. Trying to build a single metadata pipeline that ingests case notes and policy documents and meeting minutes in one pass produces a table whose columns are either too generic to be useful or too sparse to support querying.
The discipline here is conceptual before it is technical. Before any extraction or inference is run, the practitioner has to decide what the corpus is, what the unit of analysis is, and what fields are meaningful for every document in the corpus. If a field is meaningful for some documents and not others, the corpus probably contains more than one collection, and they should be processed separately and joined later if needed.
Why retrieval is the central use case
The primary reason to invest in metadata is retrieval. When a user asks a question of a document collection, the worst possible answer is one that runs the full text of every document through an LLM and hopes that the right material surfaces. That approach is slow, expensive, environmentally costly, and unreliable on collections of any meaningful size. A well-built metadata layer makes most retrieval queries deterministic. Filter by jurisdiction. Filter by date range. Filter by topic tag. Return the matching documents. The LLM is reserved for the work that actually requires it, which is usually summarization or synthesis over a small, already-relevant set of documents.
Metadata can also include short generated summaries as fields, as the examples above illustrate. A two-sentence summary of each policy document, attached as metadata, allows a search interface to scan summaries rather than full texts. Summaries are inferred fields and need to be evaluated as such, but once produced and validated, they make retrieval dramatically faster and more useful. The pattern is consistent: structured metadata at the front, full-text or vector search behind it, model reasoning at the end and only over a manageable subset.
The economic and environmental argument matters here as well. An LLM call against every document in a corpus, on every query, is wasteful by every measure. Metadata-first retrieval pushes the model to the smallest part of the workflow where it adds genuine value. The rest is database work. That is the right division of labor.
Where this leaves the practitioner
Before building any AI application on top of a document collection, decide what the collection is, what fields are meaningful across every document in it, which of those fields can be extracted and which require inference, what format will hold the records, and how each kind of field will be evaluated. Once those decisions are made, the metadata layer follows. Once the metadata layer is in place, the rest of the system has something to stand on.
Most projects skip this step and pay for it later. The chatbot underperforms. The search returns nothing useful. The dashboard double-counts records. None of these failures are model failures. They are failures of the layer beneath the model, and that layer is metadata.