The context window
Why input, thinking, and output share one budget, and why that matters

A common assumption about modern language models is that they can simply be handed a pile of documents and asked to work through them. The interfaces encourage this. There is a paperclip icon, an upload button, an offer to attach files. The implicit promise is that the model will read everything you give it and incorporate all of it into the answer. For a small number of focused documents, that promise is mostly kept. For a large pile of documents, it is not, and the reason has to do with a single underlying constraint called the context window.
The context window is the most consequential concept in working with language models, and it is the one most users never have explained to them. Almost every frustration people have with LLM behavior, including answers that miss content from the middle of a long document, sudden refusals on long conversations, costs that climb faster than expected, and outputs that feel vague when the input was specific, traces back to the context window and to how the budget inside it is being spent. Understanding what the window is and what shares it is the conceptual foundation for every other decision about how to use these systems well.
This article explains what the context window is, what fills it, why a bigger window does not solve the problem people think it solves, and what to do instead. The throughline is straightforward: the model can only attend carefully to a focused, manageable amount of material at one time, and the practitioner’s job is to give it focused, manageable material rather than crowded, mixed material.
What the context window actually is
A context window is the maximum amount of text a language model can hold in mind during a single call. Think of it as the model’s working memory for one exchange. Anything outside the window does not exist as far as the model is concerned. Anything inside the window competes for the model’s attention.
The size of the window is measured in tokens. A token is roughly three quarters of a word in English; a separate post on tokens covers this in detail. Common context windows in modern models range from around 128,000 tokens up to 1,000,000 or more, depending on the provider and the specific model. In rough terms, 128,000 tokens is somewhere around 300 pages of plain text. A million tokens is several thousand pages. These are large numbers, and the marketing around them encourages the impression that the practical limit is essentially gone. The marketing is misleading. The window is a budget, not a guarantee, and the budget gets spent on more things than people realize.
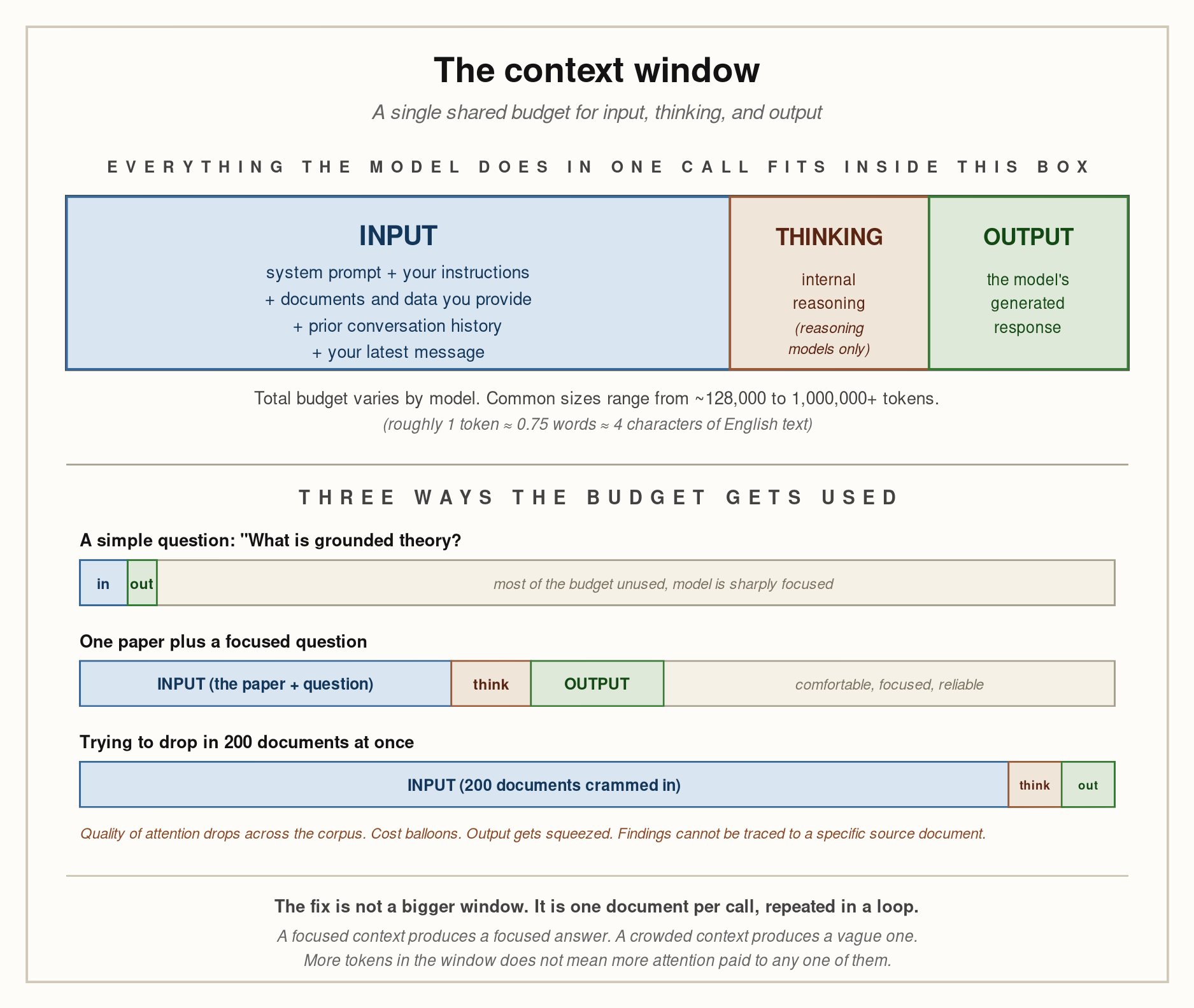
The diagram above shows the structure of the window. The single rectangle at the top represents the entire budget. Inside it, three things compete for space. The first is the input, which includes everything you and the system have told the model: the system prompt, any documents you attached, prior conversation history, and your latest message. The second is the thinking, which is the model’s internal reasoning when it is using a reasoning mode. The third is the output, which is the response the model generates back to you.
All three live inside the same window. They share the same budget. If the input takes up most of the budget, less is left for thinking and for output. If the model is asked to think extensively, fewer tokens remain for the answer. If a long conversation accumulates, the room available for the next message shrinks accordingly. The total cannot exceed the limit.
This last point is the one most people miss. The window is not just about how much you can put in. It is about how much can fit in for the entire exchange, including the answer the model has not yet generated.
What fills the input side
The input portion of the window is usually the largest, because it carries everything that has been provided to the model up to the moment of the response. Five things commonly sit here.
The system prompt is the instruction set the platform or the developer has given the model about its role and behavior. Even when you do not see it, it is there, and it consumes tokens. In a chat interface this is usually short. In a custom application it can be quite long, especially when it includes formatting rules, tone guidelines, safety constraints, and example outputs.
Attached documents are the most consequential. Every PDF, Word document, image with text, or pasted block of content occupies a share of the window proportional to its size. A long policy document might be ten thousand tokens. A research article might be six thousand. A scanned manual that has been processed into text might be twenty thousand. The total adds up quickly.
Prior conversation history accumulates as the exchange grows. Every message you have sent and every response the model has produced earlier in the conversation is included in the input on the next call, because that is how the model maintains continuity. A long conversation steadily eats into the available budget.
Tool outputs and retrieved content fill the input on every call when the system is doing retrieval-augmented generation, web search, or tool use. The retrieved chunks, the search results, the tool responses, all of it sits in the input window the next time the model is asked to respond.
The latest user message is the smallest piece, but it is still there.
When you upload a stack of documents and ask a question, the question itself is usually a few dozen tokens. The documents are tens or hundreds of thousands. The model is reading and reasoning over all of it at once, and the question is the small wave at the end of an ocean of input.
What fills thinking and output
The thinking side of the budget exists for reasoning models, which are models that produce internal step-by-step reasoning before generating a final answer. The reasoning itself consumes tokens, and the tokens come out of the same shared budget. Models can be configured to use anywhere from a few thousand to tens of thousands of thinking tokens on a single problem, depending on the difficulty. When a reasoning model gives a careful answer to a hard question, much of the work happens in that thinking region, even though the user never sees it. The thinking is real, and it is paid for in tokens.
The output side carries the model’s generated response. There is usually a separate cap on the output, often somewhere between a few thousand and a few tens of thousands of tokens, because runaway generation would otherwise consume the entire budget. When the output cap is reached, the response is cut off mid-sentence. When the input is so large that little space is left, the model produces shorter responses to fit, sometimes truncating its work without explanation.
The single most useful mental model is that the context window is one container with three rooms inside it, and what you put in one room reduces the space in the others.
Why bigger windows do not solve the problem
The temptation is to assume that as windows grow larger, the problem of fitting documents into them disappears. This is mostly wrong, for two related reasons.
The first is that attention is not uniform across the window. A robust finding across many evaluations is that models attend most carefully to material at the beginning and end of the input, and less carefully to material in the middle. This is sometimes called the lost-in-the-middle effect. Drop a hundred documents into a window and ask a question. The model will tend to surface content from the first few and the last few. Documents in the middle of the pile will be underweighted, sometimes ignored entirely, and the model will not warn you that this is happening. The output will look complete. The synthesis it offers will be incomplete in ways that are difficult to detect.
The second is that even when attention is uniform, the model has to weigh many things against each other when the input is large. A focused input lets the model concentrate. A crowded input forces the model to summarize, generalize, and smooth over differences. The result is a vaguer, less specific answer. This is especially apparent in classification, extraction, and analytic tasks, where the precision of the response is what matters. A model classifying one document at a time is reading that document and producing a label. A model classifying a hundred documents at once is producing a list of labels in a single pass, with much less attention to any one of them.
Larger windows extend the upper limit of what fits. They do not fundamentally change how attention works inside the window. The biggest model with the largest window is still better at one focused question over one focused input than at one diffuse question over a hundred mixed inputs.
The classification pipeline as the practical answer
The right way to process many documents with a model is the pattern described in the post on classification at scale. One document per call, in a loop, with a fresh context window each time. Each call has the full budget available for one focused task. The model is not splitting attention across a hundred documents. It is reading one, classifying it, and finishing. The next call starts clean.
This pattern looks like more work than dumping the corpus into a single chat session, but it produces dramatically better results. The output is structured. Each result is traceable to a specific document. Errors are visible at the level of the individual call rather than smeared across the corpus. The cost is predictable, because the per-call cost is fixed. The pattern scales to corpora of any size, because the constraint is no longer the window; it is just how many calls you are willing to make.
The general principle generalizes. When the work involves reasoning over a large body of material, do not try to fit it all into a single context window. Decompose the work into pieces that fit comfortably, run each piece in its own call, and combine the results in code afterward. The model is the engine. The pipeline is what scales it.
Practical implications
A few practical conclusions follow from all of this.
When using a chat interface for a single question over a single document, you are usually fine. The window is large enough for that, and the model’s attention is concentrated on the small amount of material in front of it. This is the use case the chat interface is best at.
When the work involves many documents, do not paste them all in. Process them one at a time, ideally through a structured pipeline. If the work has to happen in a chat interface for some reason, work on one document at a time and start a fresh conversation between documents, so that prior conversation is not crowding the window.
When a conversation gets long and the model starts behaving oddly, missing earlier context, repeating itself, generating shorter responses, the conversation has likely consumed enough of the window that the model is operating with less room than it should have. Starting a new conversation usually fixes this.
When using a reasoning model on a hard problem, leave room for thinking. A long input plus a long output plus extensive reasoning can collide with the budget in ways that produce truncation or worse performance. Smaller inputs let reasoning models reason better.
When designing a custom system, treat the context window as the most expensive resource in the pipeline. Decide what belongs in the window for each call, and what belongs in retrieval, in code, in storage. The window is for the work the model needs to see right now. Everything else lives elsewhere.
Where this leaves the practitioner
The context window is the underlying constraint that shapes almost every decision about how to use language models in serious work. It is not just an upper limit on how much fits. It is a budget shared by everything the model is doing at once, including thinking and producing the output, and the model attends most carefully when the budget is being used carefully. The interface that invites you to drop in a pile of documents is not optimized for accuracy; it is optimized for the impression that everything is possible. The work, in practice, is to keep the window focused, and to scale by repetition rather than by crowding.
A focused window produces a focused answer. A crowded window produces a vague one. Bigger numbers in the marketing materials do not change this, and the practitioner who internalizes the constraint will produce better results with smaller models than the practitioner who ignores it will produce with larger ones.